CITCON Cluj 2016
Cluj was the seventh CITCON I attended, and it's the second CITCON organized by people who first attended the conference series in Budapest (which I organized :)). But it's not about reunion of old friends, it's a super open and welcoming event, where I still keep learning, so without further ado, here are my learnings from the sessions I've attended.
Monorepos
(It was a lunch session, which I didn't attend, but we've talked about it Friday evening)
Ivan Moore suggested (and has done so in his past project(s)) not to break up your team's repo into different repos, but just have a single one and keep modules separated. Essentially he suggests a single repo per team.
The benefit of this is that you save a lot of time by not having to deal with a bunch of things, especially in the build, packaging and dependency versioning/management area - the compatible versions are always kept together.
It's recommended that you CD the artifacts, but it's actually not a requirement.
We disagreed whether the physical separation of repos is a better tool to teach people proper modularization, Ivan argued that it should be addressed on a team dynamic/process level (reviews, pairing, etc.), and not make delivery (and refactoring) harder. Note on refactoring: in Java, the equivalent of pip install -e <folder|git url> is much less practical than in Python.
Is there a limit to self organization?
It turns out that the team I work with is quite self organizing, but only within the unit of the team. @Jtf suggested to rephrase the question as Is there a limit to self organization or only to how big the self is?.
I also learned that one should be careful with terminology - the question of who owns the solution and who owns the goal is totally orthogonal to how any given team is organizes work.
At @Jtf's company they run something similar to how Valve operates - there is an internal project fair, where PO(s) propose projects, and then developers sign up for them - and it's perfectly OK if a project gets no signups.
To address the divide between who owns the goal and who the solution, properly cross functional teams can be the answer, i.e.: the PO should be part of the team and should really own goals and priorization of the goals.
There was a rather interesting quote from Alistair Cockburn that "Self organization is mutiny", because self organizing will inevitebly be pushing the boundaries.
The technique called Coherence Busting was suggested, which in high level translates to empathy/understanding where people's actions are coming from, i.e.: What has to be true for this behavior to make sense. But if you can, just ask directly :)
Randomized testing/random data generation
On the train ride to Cluj, I was playing around with py.test's test fixtures and how one can combine that, e.g.: in a shopping cart, how can one specify in a test that "I need an order for an electroncics items that is sold to an end user who paid by credit card and who used a fixed amount coupon". I've found that generating all combinations is rather easy, but to filter out the scenarios I need for a given test is hard if I don't want to write a lot of specific fixtures (e.g.: electronics_item_for_end_user_with_creditcard_with_fixed_discount), which could get out of hand fast.
One possibility could be to do some (model driven) code generation to generate all these specific fixtures, but I had the impression it might become unmaintainable/hard to understand quickly.
During the session, I used the analogy that "as if I was writing a SQL query to select the test scenarios I need", which - with the input from the other participants led to the realization that I could separate the generation of scenarios from the selection of scenarios, i.e.: I could generate all possible combinations, serialize the results somewhere before running the tests, and then inside the tests I could just query the generated ones and load them. Certainly something to experiment with further!
Continuous Delivery/Deploymnet side effects
This session was run by PJ, CTO of an online advertising firm, who described their one year journey to CD, and the kind of interesting side effects he has observed.
He has mapped out the full process from idea to profit, and looked where they could speed it up. As a CTO, he started in the domain under his control, i.e.: from commit to released to production, though as it turned out, that's quite a small slice of the full process. Later when he showed the chart to fellow executives, they were surprised by the complexity of the project. Most likely it was the result of organic growth that comes from the human/firm behavior that when one encounters a problem/road block, often the solution to fix it is to add more process to it. Quickly there was buyin to automate a solution to the root causes for which the processes were introduced.
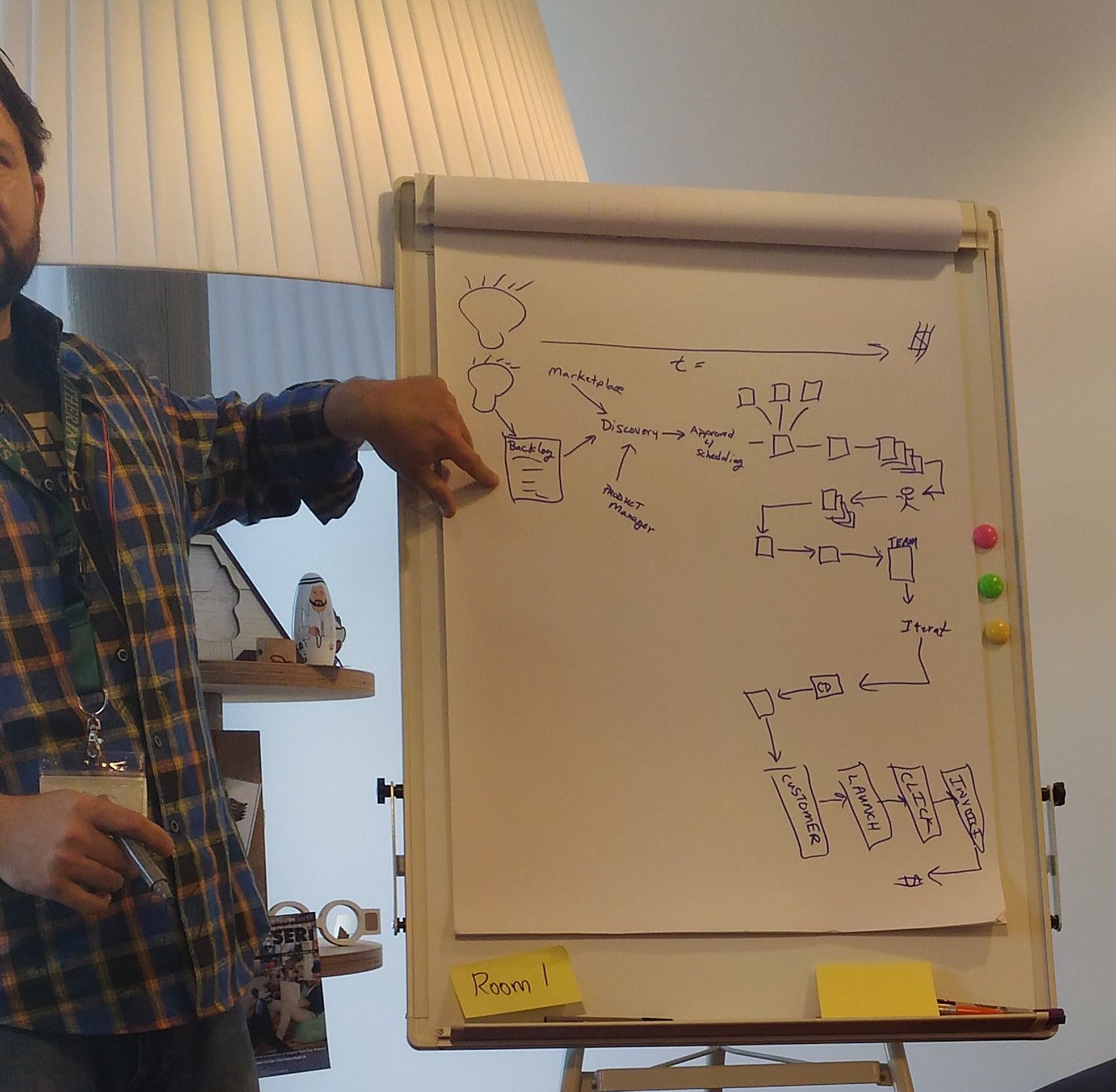
PJ told the engineers to spend the bulk of their coding time refactoring. Which people initially didn't. So he then required that 50% of the time was to be spent on refactoring, as well as 50% of the time should be pair programming. The business did protest initially (this was before the full value map), but the results quickly proved it was worth it. Before this change, it took 12.5 days to from a time the story made it to the implementation backlog to production down to 3.5 days (average), which led to happy stakeholders.
They achieved this by:
- integrating devs, testers, operations, etc. into a mixed teams, now everyone's title is "Software Creator"
- slicing stories smaller
- ship the done story when it's done, and not the end of the two weeks iteration
- to fill out the refactoring time, they've actually reduced the pure build time from 90 minutes to 3 minutes, and the commit to build ready feedback cycle from 2.5 hours (due to pending builds) to just under a cup of coffeee
PJ's observation is that if you give people metrics to strive for, they will game the system to achieve it, so if you give the right targets, great things will happen (note: it's not always easy to get the right targets :))
The refactoring eliminated the fear people had before to change the codebase.
Once they got to the time where it took 3 minutes to deploy, and 1 minute to roll back, the team actually decided to get rid of the slow end to end tests, as they could get faster feedback from production than the time it took to run those tests. However, as an online ad agency, they do have 1000s of events per second (or minutes), so they have enough data. We couldn't pin down an exact formula when exactly one can switch to production monitoring to replace their end to end tests, but the ratio of the time the team needs to go from change idea to deploy in production (i2p, idea to production) and the time the team needs to get feedback whether the change was good once it was deployed (p2f, production to feedback) is a useful one to consider where to invest your time. E.g.: if i2p = 30 mins and p2f is 3 minutes, optimizing i2p could make sense. But if i2p is an hour, and p2f is a day, maybe it doesn't. If anyone knows of some mathematics that could help here, please let me know!
As they dropped their end to end tests tests, unit tests did skyrocket in number too.
Also, just to emphasize, while in retrospect and in this presentation it could sound like smooth sailing, it wasn't, there were many mistakes. But that quickly teaches the team to focus on resiliency and recovery, i.e.: they changed there processes around to reduce the cost of an error (fine-grained feature flags (on off, enable for only some groups, etc.), rolling out to a few servers and then to the whole cluster, etc.).
Apparently New Relic supports a/b testing with monitoring, so one could compare the new release against the old one, so that's something to look into.
How do you test your organization?

Andy Parker is an engineering manager in a self organizing organization, so the question arose: what exactly should a manager do there? His answer is to gather data that could be an additional input into the kaizen (continuous improvement).
When one joins the organization, it helps to map out the company - look at the org chart, as well as how actually work gets done. Who are the key communicators? Who are people actually working with (usually across the hierarchy, even whent he only common manager they have is the CEO). This is easy to do when one is starting out, but should be remembered an actualized even when one is already part of the "daily mill". See also: static vs. dynamic org. situation
Before one starts out collecting organization, one should always start with a hypothesis (as per the scientific method). This can be the null hypothesis, i.e.: there is nothing interesting here, so observing it I'll find that everything is OK and I will just confirm that.
Some tools to do this is
- take notes - raw data when possible, even though you can't be an impartial observer of course
- beware that observation changes things, but that in itself can be valuable information. E.g.: oh, people are pairing there, let's see what they are working on! Hmm, now that I observe them, they stopped pairing and went back to working alone. Why is that?
- (with permission), record conversations and re-listen to them
-
in a meeting, draw a communication matrix -
-
who talks to whom
- are they making statements or questions?
-
how long do they talk?
-
interview team members - what is your responsibility in the team? what is others' responsibility? You can find that not everyone has the same understaning
- one, especially developers/engineers, should be careful to start with qualitative analysis, and not quantitative
Elephant Carpaccio
It's a workshop that was originally run by Alistair Cockburn, but Douglas Squirrel has adopted it to fit the one hour session limit.
As we've walked into the room, everyone was required to add a single feature to the drawing of an elephant (which started out as with a circle (head) and 4 lines (body, two legs, and the trump)). Surely we didn't create the masterpiece, but it started to resemble the elephant more and more, and as Squirrel observed, it was looking like an elephant throughout the whole process, it was just getting better/more detailed with each iteration.

His client is working with a simple kanban board that has the following columns: idea, dev working on it, testing, and live. Their goal is (which they meet more often than not) to go from idea to live in a single developer day for a story.
E.g.: their app shows graphs, and they've introduced the color picker to allow users to choose the color of the lines of their graph via the following cards:
- behind a feature toggle, release a UI button for the color picker (to learn whether or not people will actually click on it)
- when clicked, pop up a static image (to learn whether people just close the dialog, or actually click on a color)
- a functional color picker widget, which allows choosing a color, but the selected value is not used anywhere (to do UX testing with real users over the phone)
- actually persist the selected color and display that on the graph (done)
In each step, they've implemented a slice which either provided value or provided fast feedback. One benefit of fast feedback is that you can discover early enough if you are working on a feature noone needs, and can concentrate your efforts elsewhere. As opposed to layered development, where first the data storage is implemented, then the backend is implemented, and finally something is shown to the users. It's important to slice the elephant not parallel to the ground, but vertically along the line from its trump to it tail, so that it keeps looking like an elephant.
Slices work even if you only release them internally or to selected users only.
It's important how you slice - e.g.: one could say we start with a single (or two) color(s) color picker, but that would require us to implement a rather thick slice.
There is a nice flowchart to decide on how to slice stories.
In Squirrel's experience people don't tend to slice too thin, but rather they often slice the wrong way
There can be tension and tradeoff in slicing whether we take the smallest next slice to implement or we take the thing that gets us to market/money fastest. That's why the slicing session happens together with the PO and the devs.
The benefit of this approach is that estimation is eliminated, and delivery becomes more predicatable (each card is one dev day).
Usually they only plan ahead like a week or so, so they can respond to feedback without too much rework.
Context: his client is a startup still getting to the proper product - market fit.
After this overview, we did a slicing/planning session for a price calculator (each drink has a price, and there is vat, which varies from country to country).
The following cards were derived:
- calculate price on command line, in ireland only, for 1 pint of beer with a fixed price and fixed percent tax
- for
Nbeers - at a variable price (coming from the user)
- move from the command line to a (web) API (assume CD infrastructure is present already)
- and whisky and wine, but calculation can only be done for a single type at a time
- multiple types per calculation
- expand to have the UK prices/taxes too
Summary
CITCON Cluj was a blast, I've learned way more than what I squeezed into this blog post, so many thanks to Adina and the local organizers for finding a great venue and making the event happen!
Hope to see you at a CITCON next year!
Books of CITCON Cluj
These are books that were recommended either during the sessions or conversations around the conf, in no particular order
- The Future Of Management Is Teal
- Why we can't learn anything from Google / Toyota (???)
- Gun, with Occassional Music
- Research methods in anthropolgy - qualitative and quantitative approaches

